
與品質結果Q(Quality)的最佳解方")
■中方科技 / 邱培其 經理
前言
有識者皆知道P(製程參數)對Q(品質結果)的影響最大,但每個製程前後互相影響,且裡面的參數眾多,數據量又很大,到底該如何定義出某關鍵管制項目Q的最佳P組合呢?
事實上,藉由大數據與先進演算法的搭配,直接抓取機臺製程參數與品質結果找出最佳解方現在已經不是夢想,找到最佳解不但可以在少量多樣的快速變化競爭中拿到最快速的優秀成品與高利潤,更可強化企業的基因轉型成數位達人。
概念上,我們可以用大數據的概念思考,比如某一地的氣候變遷,這牽涉的時間空間、大氣、溫度變化……等變數非常多且無法掌握,可能要用多臺超級電腦耗費大量時間運算海量數據,才能得到近似值。推算到企業工廠的大數據,我們當然可以想辦法將所有製程參數與品質結果等都一股腦兒地投入超級電腦持續不斷的運算,得到相對的答案。但,租賃超級電腦的成本與持續不斷收集大量數據的運算不但成本高昂,而且CP值低,更難以推廣到其他廠區。真正有效的概念應該是掌握住工廠的重要製程參數與關鍵品質與產量項目,且知其然也知其所以然,這樣才能讓企業能掌握關鍵,並推廣到所有工廠與產品的持續優化上。
同理,依照剛剛的概念,收集有效與相對少數的關鍵因子,牽涉的大數據量就可降到工廠伺服器合理運算的範圍,相對投入成本也遠低於超級電腦的租賃成本,畢竟這是一個持續不斷內部自我優化的動作,不可能用數百萬美元乃至上億美元去購買超級電腦,也不可能長期租賃超級電腦,因此合理的投入是必要的,但前提是要合理,那麼要如何做呢?
邏輯上,首先,工廠負責此專案的主事者(稱之為CDO數位主管)必須先了解到自己工廠的現況,假設人機料法環境都已經被定義且標準化,大數據的基礎就已經建立好。在此情況下,如果能有計畫的蒐集完整且關鍵的P,並將其關聯正確的Q,利用AIQ系統收集一段時間的大數據,建立關鍵的數學模型,開始試誤與自我優化。經過一段時間源源不斷的真實世界大數據收集與模型優化,就可以建立出正確的數學模型,找到此階段正確的解方。具體作法如下:
- 先依據工廠高階主管與生技、研發、品管等人員組成專案小組,訂定某項特定改善目標與針對此目標收集關鍵製程與產量、品質資料。
- 品管統計專業人員訂定去除雜訊的方法,並獲得小組成員確認。
- 收集各製程相關關鍵參數,並確認設備數據準確性與重現性。
- 利用AIQ數學模型了解P&Q的關聯性,將關聯性高的項目作關聯與開始建立數學模型。
- 利用此模型驗算收集的大數據並初步判定是否有效,若有效則持續不斷收集新大數據,持續一段時間多次驗證。
- 確認此模型有效,將其存入AIQ,之後在同類情境下以此模型預測與判定,並於之後收集新數據時不斷驗證與優化。
- 此過程不斷重複。
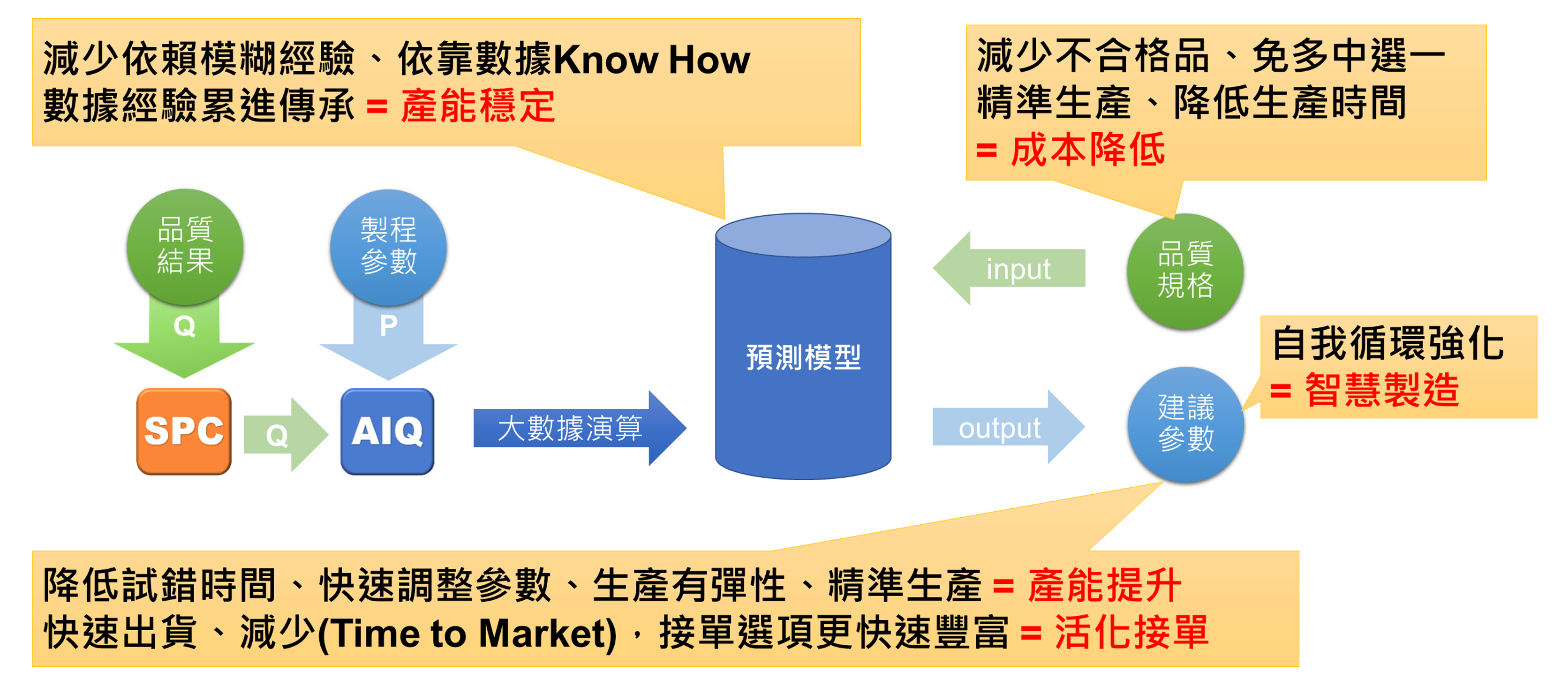
在此過程中,其實應用的技術主要是【製程&品質的大數據應用】以下是應用簡述,分別為「資料擷取-Data Mining」、「數值前置處理-Processing」、「數值即時監控- Monitor」、「數值分析-EDA」、「進階數據整合-Integration」。
資料擷取-Data Mining
邁向提升生產力的第一步,就是要先收集數據。將機臺的裡面的參數標記後擷取,並透過系統串接,進入AIQ資料庫開發應用。此部分的資料量可能相當龐大,如果有經驗的製程人員,可以只取確認最有影響力的參數。當然也可以先全部收集,經過一段時間的分析,得到較確定的數學模型後再篩減。
數值前置處理能力-Processing
AIQ擁有多樣的數學演算工具,可將巨量的製程參數資料,從原本龐大且雜亂,導致影響效能及分析結果的狀態,去蕪存菁、淬鍊價值,透過下列方法如:
過濾(Filter)
設定條件進行篩選,依製程特性自動剔除不適合或出軌的數值、選具穩定趨勢之有效數值進行後續處理。
重新取樣(Resample)
依照數值曲線特性,篩選數值取樣內容,在不改變原有曲線特性的前提下,取得具有代表性的數據,減少後續儲存空間與演算時間的浪費。
曲線擬合(Curve Fitting)
如資料包含一維輸入及輸出,則此數學模型(線性、二次、三次……)可經由多點數據擬合一條曲線,並進行後續分析。
數值即時監控-Monitor
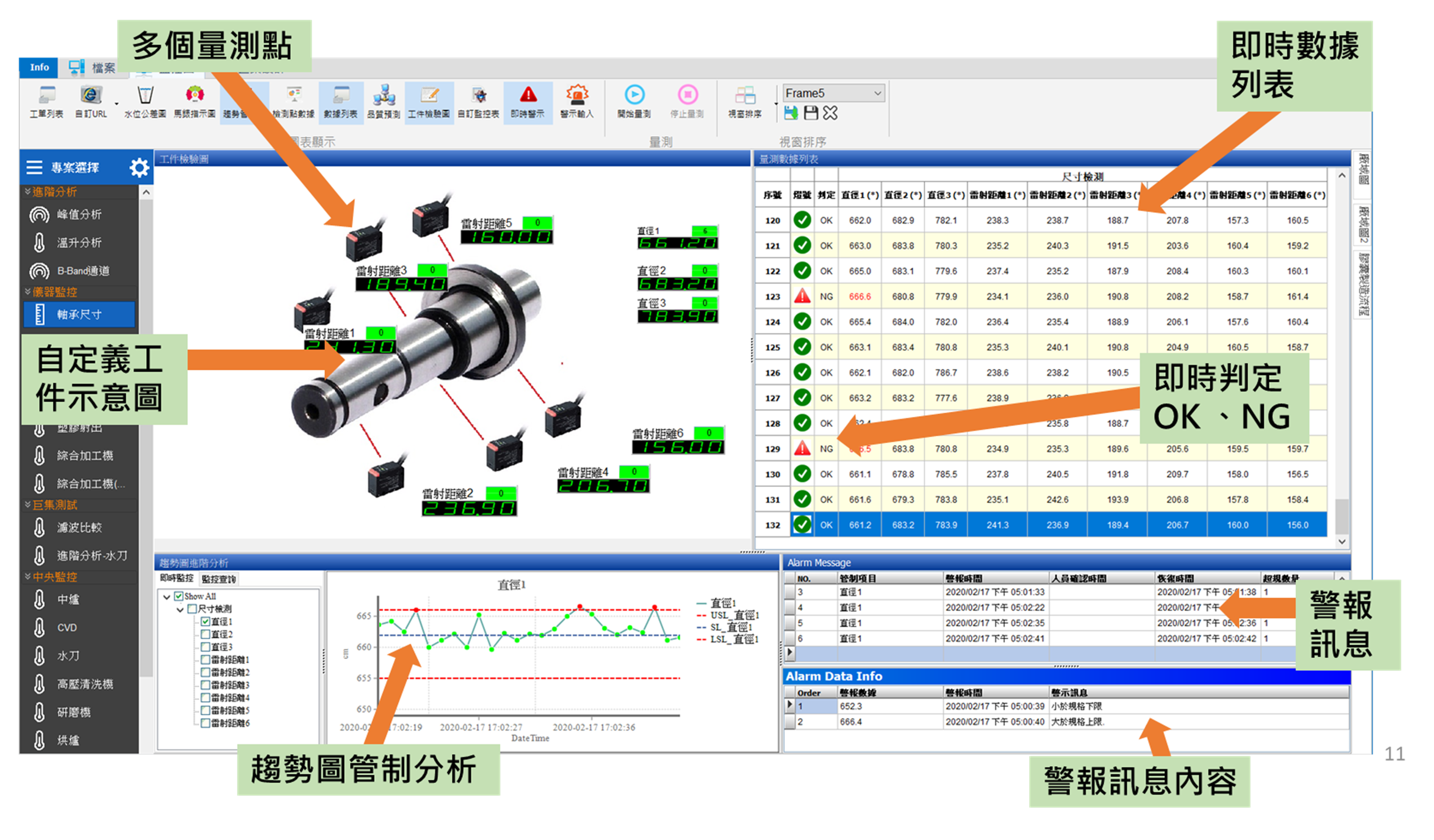
依據需要顯示的製程參數與管制項目,設定顯示的方式,做看板或是異常監控的各種顯示(如圖2~圖5),以下是幾個常見的方式:
- 工件即時監測與異常警示畫面(如圖2);
- 區域與廠區即時監測與異常警示畫面(如圖3);
- 中央監控──戰情中心(如圖4);
- 中央監控──生產看板(如圖5)。


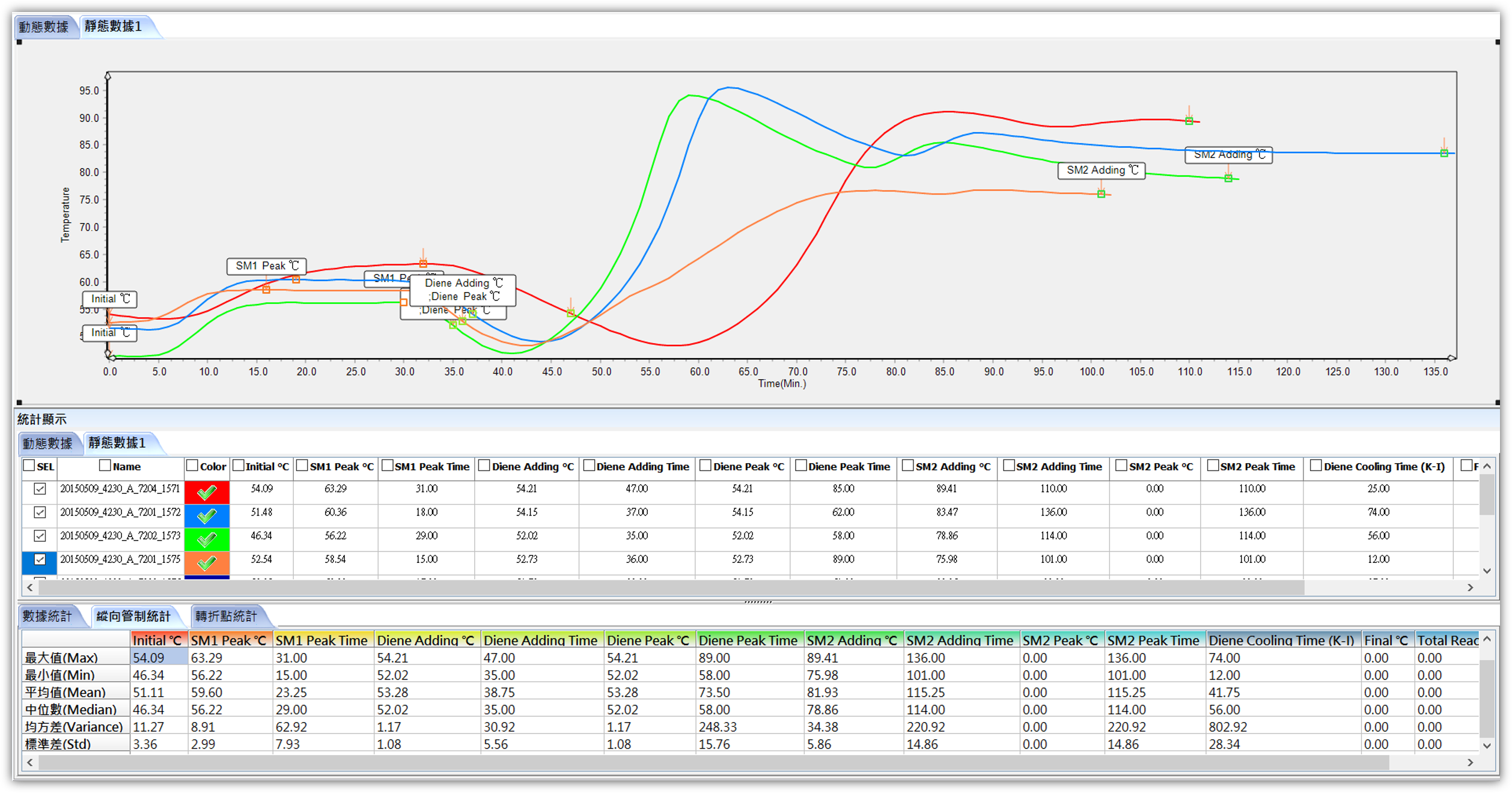
工程曲線分析&管制條件設定-EDA
EDA可整合各種製程參數,針對產品製程特性,建立標準統計分析模型,得出關鍵數值,以利進行自動化管制。如:找出配方中加入藥劑溶劑的最佳時間點、濃度、劑量,並進而選取該時域之數值變化,進行上下限或自訂規則的管制,超規異常也可透過EMAIL或警示燈提供訊息給相關人員。如何時升溫、加入催化劑、依據偵測值調整配方…..在現代高階特用化學品與ESG的環境回收改良上,利用大數據與科學方法,可有效協助企業不斷自我優化與競爭力。
進階數據整合-Integration
此議題最好是從應用面來說,主要就是跨站跨系統的整合應用,說明如下:
從品質結果,跨站分析找出異常製程
- 遭遇問題:過去當異常發生而產生不良品時,由於時間差,往往無法快速追蹤異常發生原因,並修正異常製程,導致成本的損失。更糟的是,這是惡性循環。
- 解決方式:當SPC檢測發現品質異常時,可透過工單、批號……等關聯,由AIQ連結對應該產品的製程參數履歷,可快速檢視所有製造過程中的製程參數。亦可透過關聯分析,立即縮小問題範圍,找出異常製程。自動化系統可即時驗證設想是否正確,讓失敗機會不再發生。
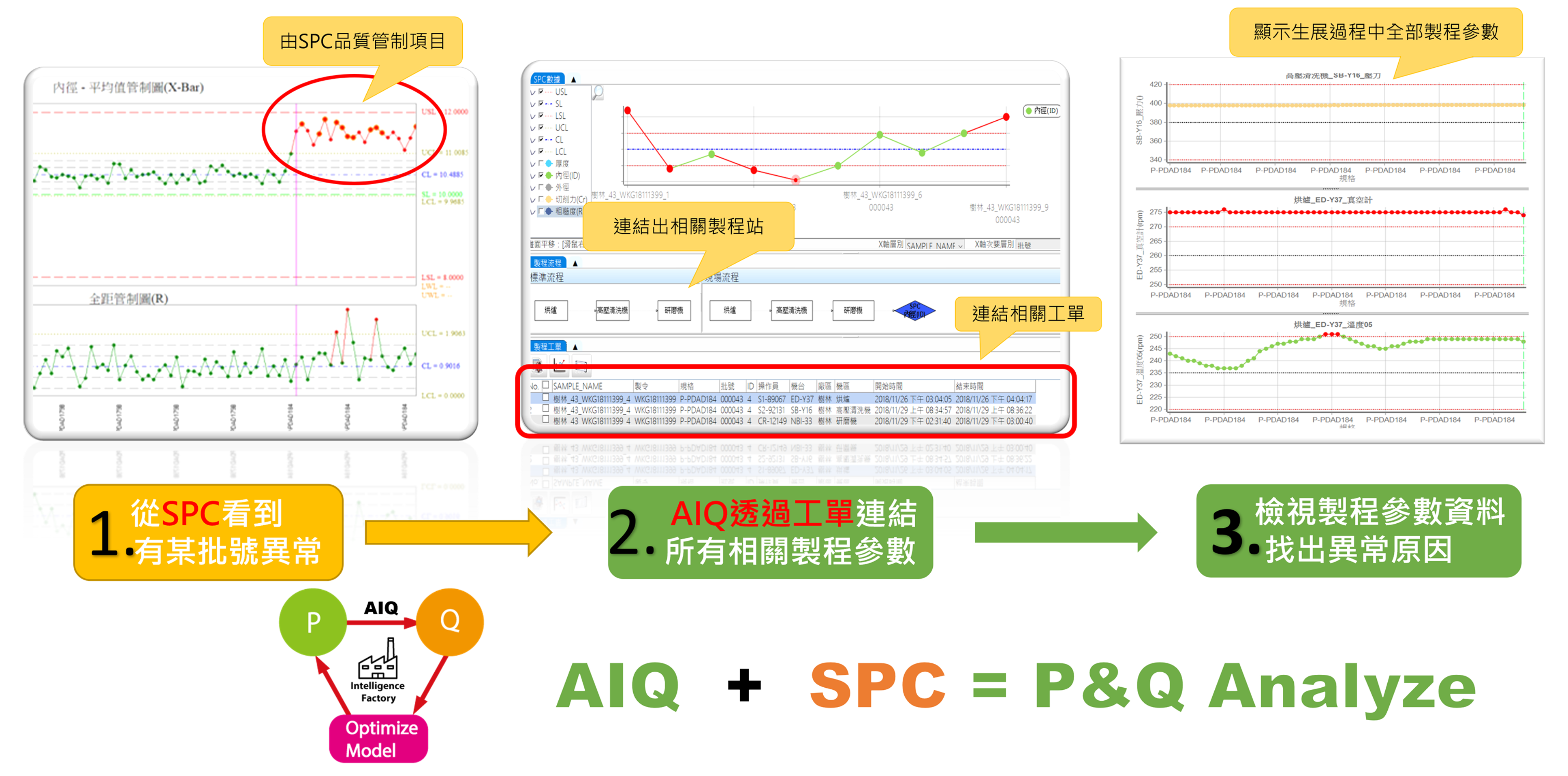
找出最影響品質的關鍵製程因子
在眾多製程站別中,透過製程參數與品質檢驗資料的大數據分析,可關聯出各製程參數影響品質結果的關係程度比重,並找出最影響品質的關鍵製程因子。後續可以利用這些因子建立數學模型,並自動優化驗證模型達到數位自我改善AI系統的目的。
品質預測
大數據應用在設備與品質預測上,可透過監控製程參數,建立數學模型,預測產品品質。並可透過預測模型,提早發現,提早修正製程參數或是找到變異原因,進而防止品質異常,也能避免不良品流到下游製程浪費產能。
應用範例說明-Example
以下範例為真實範例,但數據內容與圖形皆為模擬非真實,請讀者有疑問時可以跟我們聯絡,謝謝。
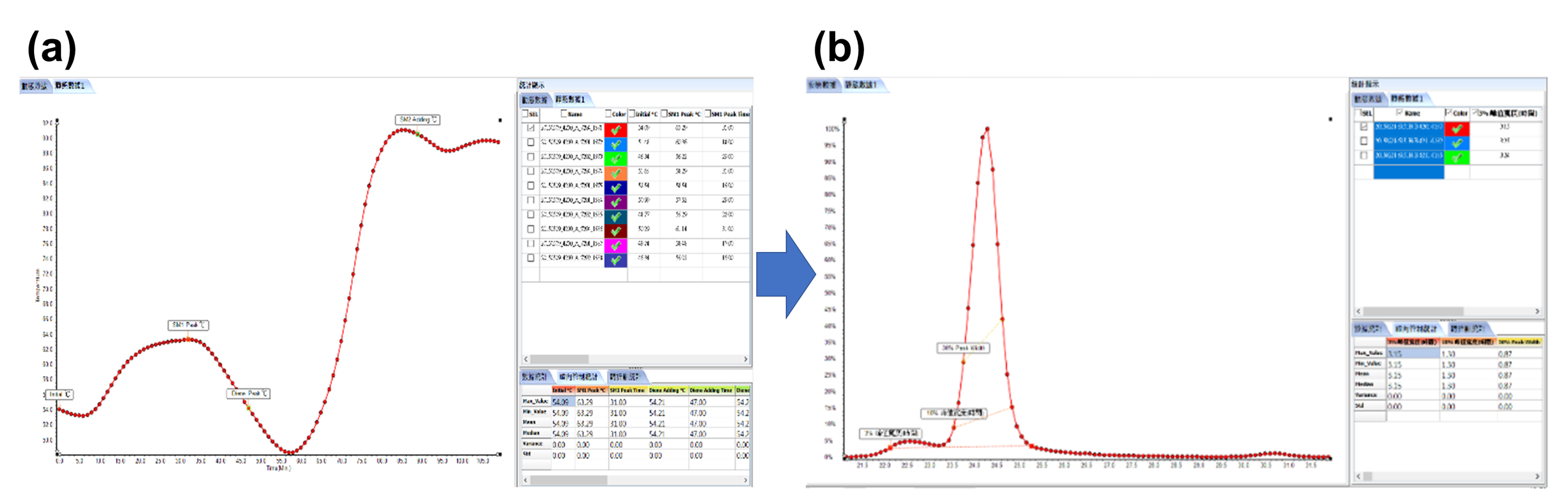
XX塑化為護國XX之電子化學品供應商,該公司電子特化廠長希望增加生產效率,自2010年起開始抓取每批生產重要製程參數10餘個,在轉化率1.2%以內希望可以減少每爐的反應時間,減少時間就是增加生產效率。該司的化學反應以爐溫升溫曲線來說,有四大類(進料溫度、升溫10-15分鐘的斜率、催化劑加入後3分鐘的爐溫斜率、頂點溫度及時間),如圖8(a)。
經過轉化與資料重新整理,以爐溫與配方控制來說,數據經過高斯轉化並重新利用篩選變化值後,此圖形可轉化為如圖8(b),利用此模型,接著我們重新調整配方模擬參數與圖形,可得到接近最佳解,每爐升溫前五分鐘增加熱水投入,讓蒸汽量提升,將可降低開始濃度,並可讓爐溫升溫曲線斜率在較短時間反應到預定斜率,在第二階段反應後壓力到達3.5g時將反應劑投入反應槽並加溫至XX度,反應時間將同步減少3%-4%,將此部分資料建立數學模型並開始實驗,可得到總反應時間減少7-8%的初步結果。
當然,實際上需要依此方向做多次實驗並且調整各項製程參數條件,但經過此科學化的方法,並依此調整各項最有影響力的參數,就可以在合理時間內達到改善製程反應時間的目的,並進而衍伸到其他類似需要改善的領域,因為這是可以推估的科學方法,如塑化反應在模具噴嘴的溫度,如加料後塑膠射出的壓力與溫度以及時間,各種料件反應與融合的最佳時間,都是可以後續探討的課題。
結語
現在是最適合塑膠射出與沖壓產業轉型智慧製造的大好時機,硬軟體與自動化環境皆已發展成熟,又有許多專案計畫的支持,趁著整個亞洲地區成本都在增加的情況下,增加智能智造的核心能力將是我們拉開與其他地區產品之差距的絕佳機會,希望大家能盡快投入心力,讓工業4.0的智慧製造能奠定強大的基礎,更加強化我們在國際上的競爭力!加油!
如有任何疑問或是應用上的問題,歡迎訪問以下網站:www.midfun.com.tw ■
