
在塑膠射出成型產業上的應用")
■科盛科技 / 簡錦昌 副總經理
什麼是大語言模型(LLM)?
大語言模型(Large Language Model, LLM)是人工智慧領域中一種基於深度學習的技術,它通過處理大量的文本資料來理解、生成和翻譯自然語言。這些模型以龐大的參數規模為特點,並利用了現代神經網路架構,尤其是變換器(Transformer)架構,使得它們在自然語言處理(NLP)任務中表現出色。
大語言模型通常由數十億甚至上千億個參數構成。這些參數是在大量的文本資料上訓練得到的,通過深度學習演算法來優化。訓練一個大語言模型需要巨大的計算資源,通常使用數百個GPU或TPU並行處理,以處理海量的資料集。

常見的LLM應用方式
ChatGPT就是一種LLM,相信大家都有接觸過,只要在聊天框中輸入問題或請求,例如撰寫文章、翻譯文本或生成程式碼,等待幾秒鐘,ChatGPT將自動生成文字。如果需要進一步調整輸出,可以繼續與其互動,輸入更具體的指令或要求。大語言模型的應用範圍非常廣泛。它們在各種自然語言處理任務中表現優異,常見的應用包括:
- 自然語言生成
LLM能夠生成流暢且連貫的文本,常用於自動化內容生成、寫作輔助和對話系統。
- 機器翻譯
通過理解多種語言之間的複雜關係,LLM可以進行高品質的語言翻譯。
- 文本摘要
LLM能夠自動從長文檔中提取關鍵內容,生成簡短的摘要。
- 對話系統
基於LLM的聊天機器人能夠與人類進行自然的對話,並且能夠理解上下文進行合理的回復。
- 資訊檢索與問答系統
LLM可以從龐大的資料庫中檢索資訊,並根據問題生成準確的答案。
LLM可否應用在射出成型產業?
像ChatGPT或Copilot這樣的LLM工具,對於通用和泛用型的問答表現得相當出色,因為它們是基於廣泛的多領域數據進行訓練的。然而,當面對工業領域的專業問題時,它們往往會遇到挑戰。這是由於工業領域通常涉及高度專門化的知識和特定的技術術語,而這些知識和術語在模型的訓練數據中可能並沒有得到充分的代表。結果,這些工具在回答工業專業問題時,可能會顯得不夠準確,甚至可能提供錯誤或不完整的資訊,就像大家常說的「一本正經地胡說八道」,也因此無法滿足工業領域對精確性和專業性的要求。
例如,我嘗試在ChatGPT上詢問(如圖2所示),我的提問是:「我有一個塑膠射出的產品,使用的材料是ABS,使用的加工溫度是220°C,生產出的產品會有白色的流動痕跡,請問該如何處理?」從ChatGPT的回答中,條列了各種可能性,但是沒有辦法得到一個明確可行的作法。如果回覆的內容是之前企業內部遇到問題的解決方法,那對我將會是很大的幫助。

LLM之所以會有這樣的回覆,主要原因包括以下幾點:
- 數據訓練的不均衡
LLM通常基於網路上的開放文本進行訓練,這些文本更側重於通用知識,而工業領域的專業知識和技術資料通常不在這些通用語料的範疇內。即使有,也往往數量有限,導致模型對於工業專業知識的掌握深度不足。
- 專業知識的局限性
LLM雖然在一般知識上有很強的理解能力,但它們缺乏針對特定工業領域的深度專業知識。工業領域的問題通常涉及高度專業化的術語、概念和流程,而這些可能並未被模型充分訓練或理解。
- 數據隱私與專有性
工業數據通常是專有的且高度的機密性,企業不會輕易公開這些數據,因此模型在訓練過程中無法接觸到足夠的相關資料。這限制了LLM在工業領域中的表現。
建立企業內部自己的LLM
為了解決LLM在處理塑膠射出成型領域專業問題時顯得吃力的問題,一般會建立一套企業內部自己的問答服務系統並搭配一套開源的LLM模型,此外,為了讓開源LLM模型的知識及用字可以滿足工業領域對精確性和專業性的要求,可以對LLM考慮加入以下幾種方法:
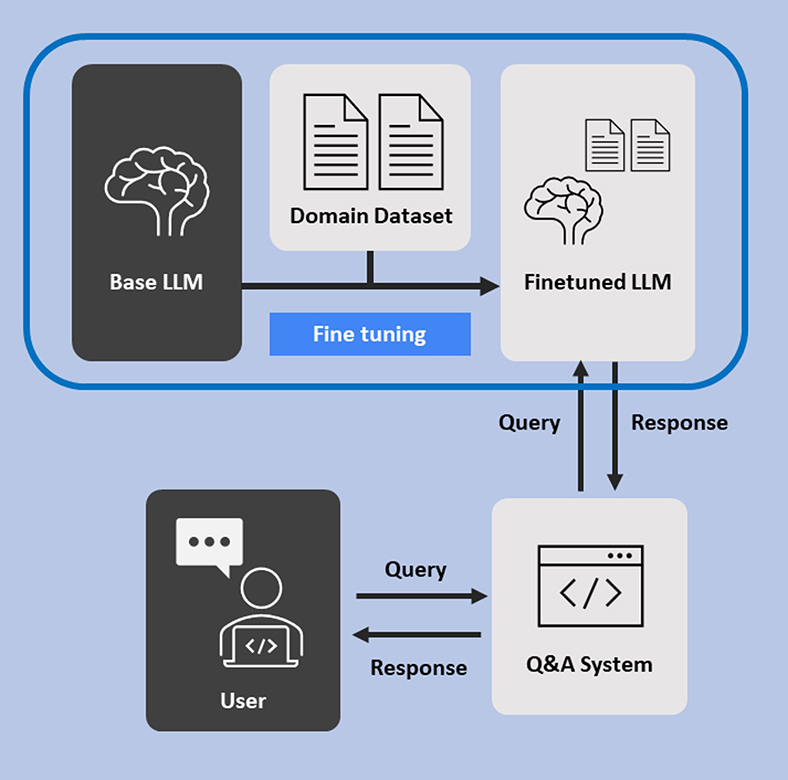
- 模型微調(Fine-Tuning)──以專業數據進行微調
如圖3所示,將開源的LLM在工業領域的專業數據上進行微調,這樣可以讓模型學習到更具體的專業知識和術語。這些專業數據可以來自技術文檔、操作手冊、故障報告和行業研究等,定期使用新的專業數據來微調模型,以保持其在工業應用中的準確性和相關性。為了確保模型能夠有效學習新的專業知識,可能需要對輸入數據進行清洗和標註,以提高數據質量。完成微調後,模型會更加熟悉特定領域的專有術語和問題情境,從而在該領域的問答或文本生成任務中表現得更準確和專業。這一過程不僅增強了模型的實用性,還能更好地滿足企業內部的具體需求。
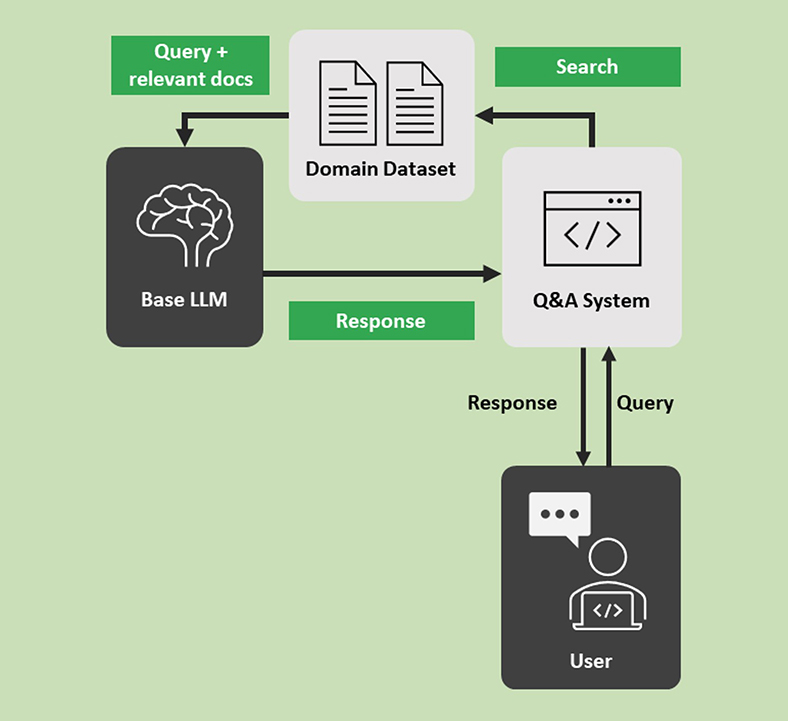
- 擷取增強生成(Retrieval-Augmented Generation, RAG)
如圖4所示,擷取增強生成(Retrieval-Augmented Generation, RAG)是提升LLM在專業領域表現的一種有效技術。RAG將資訊檢索與生成模型相結合,通過檢索相關資料來輔助生成更準確的回答。在RAG的實施過程中,首先需要構建或接入一個專業的知識庫,該知識庫通常由企業內部的文檔、專業資料、數據庫或網絡資料組成。當用戶提出問題時,檢索系統首先在知識庫中找到與問題相關的文檔或段落。這些檢索結果作為上下文資訊,與原始問題一起被輸入到LLM中。
LLM在生成答案時,不僅依賴於自身訓練過的知識,還可以參考檢索到的具體資訊,從而生成更具針對性和準確性的回答。這種方法特別適合處理需要精確和專業知識的問題,如技術支持、產品資訊查詢等。
RAG結合了檢索的高覆蓋率和生成的靈活性,顯著提高了LLM在專業應用中的實用性,特別是在處理模糊問題或需要高精度資訊的場景下。這種方法不僅增強了模型的專業性,還能動態更新知識庫,以適應快速變化的業務需求。
透過模型微調(Fine-Tuning)或擷取增強生成(RAG)的方式,都可以幫助泛用型的開源LLM模型滿足工業領域對精確性和專業性的要求,並應用在企業內部的問答服務上。
結論
總的來說,大語言模型代表了人工智慧領域的一次重大進步,其強大的語言理解和生成能力為大家的創新提供了新動力。除了在一般領域知識的文字生成上,對於塑膠射出成型專業領語的知識,可以透過進行微調(fine-tuning)或RAG的方式來訓練模型,使模型不僅能生成高質量的回應,還能在回應中融合最新的專業知識,滿足企業動態的需求。從而在專業領域中提供更加精確和有價值的答案。
隨著技術的不斷進步,LLM 將在產業升級中扮演愈加重要的角色,為企業帶來持續的競爭優勢,有望在更多場景中發揮更大的作用。
話說回來,你會不會覺得這篇文章也是LLM產生的呢?
